
(temporary) URL of the web app: http://bioimages.vanderbilt.edu/tang-song.html
Background
This fall, the Semantic Web Working Group at Vanderbilt University has been learning about applying Linked Data technologies to practical problems, and as an exercise, we have been working with Tracy Miller's dataset on the architecture of buildings at Chinese temple sites (referred to in the rest of this post as the tang-song dataset). In an earlier post, I talked a little bit about how we turned spreadsheets containing her data into RDF. This required first deciding on a graph model that linked one to many buildings to the temple sites at which they were located. The model uses the PeriodO ontology to describe the dynasties over which the temple sites were constructed, and generally uses the W3C Time Ontology to model time relationships. Wherever possible, sites were linked to the Getty Thesaurus of Geographic Names (TGN) records for the places where the sites were located. The model also uses generic Dublin Core and WGS84 Basic Geo vocabularies plus some Schema.org terms as necessary to link everything together.
{kind=link}
The tang-song temple/building graph (in Turtle serialization) is now "done" in the sense that we are now using it to "do" things. It will continue to evolve as we add triples for the architectural features and links to the images of the buildings, which have not yet been included. But it's done enough that we can now play with using the data to do useful things by loading them into a triplestore and running SPARQL queries on them.
In this post, I'm going to talk about a web application that I've put together that generates SPARQL queries based on user input, then takes the results and generates some useful output in the browser about tang-song temple buildings.[1] For those of you who do not have enough patience to read the gory details and just want to play with the application, it is online at a temporary location. I won't promise that it will stay there - eventually it will probably be linked to http://rdf.library.vanderbilt.edu/.
The application has two components: a Bootstrap-based HTML page and a jQuery-based Javascript script that's called by the HTML page. The HTML page does not have to be at any particular location - it can be run as a local file as long as the Javascript script file is in the same directory (and assuming that the Vanderbilt Heard Library SPARQL endpoint is functioning and has the tang-song graph loaded). So even if you can't find the page online, you can just download the HTML and Javascript files to a folder somewhere and open the HTML page in a browser. If you do that, you can also hack the Javascript "live" and see the effects by just reloading the HTML page. One other note: if you intend to hack the Javascript, make sure that your text editor loads it as UTF-8 character encoding, or you might lose the Chinese characters.
By the way, the Chinese that you see on the web pages was generated by Google Translate, so my apologies to native speakers. Hopefully the Chinese-speaking members of our working group can help me clean it up.
An aside about data munging
I wanted to mention as an aside that I did make use of the giant mass of Getty TGN triples that I laboriously loaded into Blazegraph (a painful process described in a recent blog post). I used a SPARQL query that used the existing Chinese names for counties/cities and provinces in the tang-song dataset to find the Getty TGN URIs for the lowest political subdivisions in which the temple site was located. Those URIs were added back into to the tang-song graph and I subsequently ran another query to find the Latin Pinyin transliterations for the counties/cities from the TGN graph (something that we did not originally have in the tang-song dataset and didn't want to have to look up manually).
Originally I was going to blog about the experience, but the query that I ran was just a hack of the last one that I described in the recent post. I decided it wasn't interesting enough to blog about. However, the experience did drive home the very serious problem related to named graphs that I wrote about in the "Take-homes..." section of that earlier post. I had originally loaded the tang-song graph into the Blazegraph triplestore (i.e. "BigData") without specifying a named graph for it (necessary because I had stupidly not designated the Getty TGN triples as part of a named graph, either). Now we had an updated tang-song graph in which we had changed many of the URIs. When I loaded it into the triplestore (also not as part of a named graph), those triples were also with the triples from the outdated graph and I started getting hits for the bad URIs as well as the good.
Because the bad triples weren't part of a named graph, there wasn't any easy way (as far as I know) in Blazegraph to remove them without dropping the whole default graph, including the Getty TGN triples that took me three days to load. I managed to use an un-elegant workaround to get the Pinyin transliterations that I needed, but it became clear to me that eventually I was going to have to drop the whole default graph, reload the Getty TGN graph, and make sure that I was careful to only add triples to named graphs from that point forward.
This is not a problem that we have with the Callimachus installation that we are currently using at http://rdf.library.vanderbilt.edu/ because it automatically keeps track of the triples that were included in a particular file that was uploaded. If you upload a new version of that file, it will automatically replace the triples that were in the old version of the file. This is kind of clunky, because it treats each file as a named graph rather than letting you specify the URI for the graph, but at least you can manage sets of triples in some manner. If we replace the Callimachus endpoint with Blazegraph in the future (which is likely), we will have to be careful about specifying each upload as part of a named graph.
General description of how the web app works
Here's a simplified version of how the web app works.1. When the page loads, the Javascript fires a series of queries to the Heard Library SPARQL endpoint to find out what Chinese provinces and what temple sites are represented in the graph. A critical piece of these queries is specifying which geo:SpatialThing instances in the triplestore are actually temple sites. That's done with this triple pattern:
?site <http://www.geonames.org/ontology#featureCode> <http://www.geonames.org/ontology#S.ANS>.
The feature code gn:S.ANS is described in the GeoNames ontology as "a place where archeological remains, old structures, or cultural artifacts are located", which pretty much describes the temple sites and differentiates them from other geo:SpatialThings in the triplestore.
2. The endpoint sends the query results back in XML format.
3. The script uses jQuery functions to parse the XML and pull out the names of the provinces and sites. It then inserts them into the dropdown selection lists on the web page. One very fun aspect of this is that the queries specify whether the results should include names in Pinyin transliteration or in simplified Chinese characters. The choice of English (i.e. Pinyin when there isn't an actual English name) vs. Chinese is one of the options offered on the web page. (In contrast to the dynamically populated province and site dropdown lists, the dynasty dropdown list is hard-coded in the Javascript, since it is fixed for the dataset.)
4. The temple site dropdown is more complicated than the other three, whose options don't change interactively (other than to be displayed in alternate languages). When one of the first three dropdowns (Language, Province, or Dynasty) is changed, a new temple site query is sent and the temple site dropdown options are screened based on the choices in the boxes above. So for example, if "Jin" is selected as the dynasty, the options displayed on the temple site dropdown are reduced to only sites whose period of construction included the Jin dynasty.
5. Once the options are selected to the user's satisfaction, clicking on the Search button fires another SPARQL query to the endpoint asking for names of buildings (in Chinese characters, Pinyin, and English as available) for sites that meet the screening criteria. The query also requests the geocoordinates of the buildings if they are available.
6. The results XML is parsed and the returned values are used to create HTML that is then inserted into the page. If the geocordinates exist, they are inserted into strings that load two sorts of Google maps onto the page. One shows the site location on a political map at lower magnification and the other shows the Google Earth view at a magnification where the orientation of the buildings can be seen. (See the screenshot at the top of this page for examples.)
One thing that is clear about this method is that things don't happen instantaneously. Depending on how long it take the server to execute the query, there may be a noticeable delay before the results of the query are injected into the page. For that reason, there is a "spinner" at the bottom of the page next to the "Search" button that indicates that the user must wait for the results to come back.
Details of generating the SPARQL query
I won't go into the details of the HTML, since it's pretty standard - it loads the Bootstrap script to create the responsive design of the page, and also sets up the buttons and dropdown lists. The tang-song.js Javascript is more interesting.
There are a number of places in the Javascript where SPARQL queries are generated. Here is an example: the query that asks what provinces are referenced in the dataset:
var string = 'SELECT DISTINCT ?province WHERE {'
+'?site <http://www.geonames.org/ontology#featureCode> <http://www.geonames.org/ontology#S.ANS>.'
+'?site <http://rs.tdwg.org/dwc/terms/stateProvince> ?province.'
+"FILTER (lang(?province)='" + languageTag + "')"
+'}'
+'ORDER BY ASC(?province)';
var encodedQuery = encodeURIComponent(string);
The query is constructed by concatenating each of the lines of the query into one long string - they are concatenated on separate lines just to make it easier for a programmer to see the individual triple patterns of the query. The variable languageTag contains the IETF language tag for the desired version of the page (zh-latn-pinyin for English and zh-hans for simplified Chinese characters), and is inserted in the appropriate place to filter the results by language. The results are ordered alphabetically so that when the list comes back from the server it won't need to be sorted.
The actual query is made by an HTTP GET to the endpoint with the query appended to the URL like this:
'http://rdf.library.vanderbilt.edu/sparql?query=' + encodedQuery
The query has to be URL-encoded so that spaces and other characters that are "bad" for URLs are escaped.
On of the problems with debugging a program like this is knowing why it has failed when nothing happens. I leaned very heavily on Chrome's developer tools that can be accessed from the Customize menu in the upper right corner of the browser. Choose "More tools", then "Developer tools" from the menu. Click on the Network tab to see what is happening when the page runs. Here's what it looks like when the page loads:

The last two items on the list at the right are the two SPARQL queries that load the province and temple site dropdown lists. If you click on the second to last item, you can see a breakdown of the request URL, headers, and the query string in unencoded form:

At the top you can see the ugly long URL that the program created by concatenating all of the query pieces and URLencoding it. At the bottom is a decoded view. You can actually copy and paste the decoded view into the Heard Library SPARQL endpoint "sandbox" at http://rdf.library.vanderbilt.edu/sparql?view in order to debug. When I'm debugging, after pasting I go ahead and add the hard returns after each period to make the query less confusing. Sometimes that in itself is enough to let me know what was wrong with it.
The actual sending and receiving of the query is done by jQuery using the .ajax function:
$.ajax({
type: 'GET',
url: 'http://rdf.library.vanderbilt.edu/sparql?query=' + encodedQuery,
headers: {
Accept: 'application/sparql-results+xml'
},
success: parseProvinceXml
});
The Callimachus endpoint only supports XML results, but other SPARQL applications support JSON results, which would probably be easier for the Javascript to ingest. The returned XML gets passed into an XML parsing function.
Details of handling the response
Of the various SPARQL queries generated by the script, the most complicated response that comes back from the endpoint is the one that returns the data from clicking on the Search button. The query requests a number of variables:
SELECT DISTINCT ?siteName ?buildingNameEn ?buildingNameZh ?buildingNameLatn ?lat ?long WHERE {...}
that are needed to generate the desired web page components.
If you run the query directly in the Heard Library's sandbox, the results get formatted into tabular form with each of the requested variables as a column header:

This is a bit misleading, because that's really nothing like the way the results come back from the endpoint when the query is made via HTTP. Rather, the XML that comes back after the HTTP request looks like this:
<?xml version='1.0' encoding='UTF-8'?>
<sparql xmlns='http://www.w3.org/2005/sparql-results#'>
<head>
<variable name='siteName'/>
<variable name='buildingNameEn'/>
<variable name='buildingNameZh'/>
<variable name='buildingNameLatn'/>
<variable name='lat'/>
<variable name='long'/>
</head>
<results>
<result>
<binding name='buildingNameLatn'>
<literal xml:lang='zh-latn-pinyin'>Guanyinge</literal>
</binding>
<binding name='buildingNameZh'>
<literal xml:lang='zh-hans'>山門</literal>
</binding>
<binding name='long'>
<literal>117.3966666</literal>
</binding>
<binding name='lat'>
<literal>40.04408333</literal>
</binding>
<binding name='siteName'>
<literal xml:lang='zh-latn-pinyin'>Dulesi</literal>
</binding>
</result>
<result>
<binding name='buildingNameLatn'>
<literal xml:lang='zh-latn-pinyin'>Shanmen</literal>
</binding>
<binding name='buildingNameZh'>
<literal xml:lang='zh-hans'>觀音閣</literal>
</binding>
<binding name='long'>
<literal>117.3966833</literal>
</binding>
<binding name='lat'>
<literal>40.0438</literal>
</binding>
<binding name='siteName'>
<literal xml:lang='zh-latn-pinyin'>Dulesi</literal>
</binding>
</result>
</results>
</sparql>
In order to make use of the results, they have to be pulled out of the appropriate place in the XML, which would be a real pain if it weren't for some helpful jQuery functions. The parseXml function at line 330 of the script uses a .find method to get the values. Here's an example for the ?lat variable:
$(this).find("binding[name='lat']").each(function() {
latitude=$(this).find("literal").text();
});
that assigns the result to the variable latitude. Once the necessary strings are pulled from the XML, they are joined together into HTML as necessary to create the desired page content. For example, here's how I made the cool little Google Earth view of the temples:
html='<img src="http://maps.googleapis.com/maps/api/staticmap?center='+latitude+','+longitude+'&maptype=hybrid&zoom=18&size=300x300&markers=color:green%7C'+latitude+','+longitude+'&sensor=false"/>'
with the latitude and longitude variables inserted into the appropriate places. The zoom can be controlled to get the desired magnification. zoom=18 was good to show the buildings and zoom=11 was nice to show where the temple site was on a map of an appropriate scale to show the city in which the temple was located.
Why bother with SPARQL and RDF?
One question that you may be wondering about is why one should bother with creating an RDF graph database, then generate web pages by populating them with content retrieved from the database through a SPARQL endpoint? Why not just acquire JSON from "traditional" web services? I am not really the right person to be answering this question since I'm not a programmer or web designer. However, I think that the answer lies in the fact that there is really no limit to the complexity of SPARQL queries that can be sent to the endpoint. A provider of web services will probably describe their API and tell users what search parameters to use to acquire specific kinds of information. In contrast, any kind of information can be retrieved from a SPARQL endpoint if the programmer of the client understands the structure of the graph stored in the endpoint.
There isn't really any advantage of using SPARQL for retrieving information like the list of dynasties as in the earlier example. One could just provide a search parameter for that in an API. However, the dynasty search is considerably more complicated as I will now describe.
"Reasoning" about ranges of dynasties
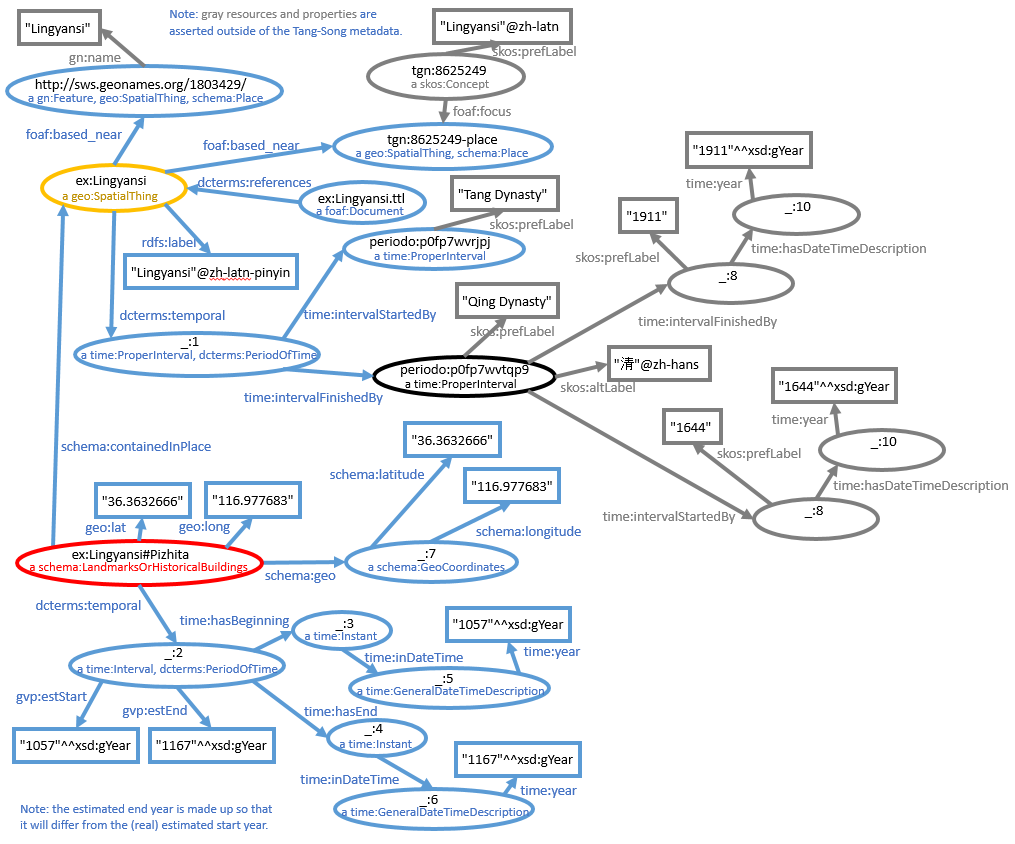
Tracy's original data had a description of the range of dynasties over which the temple was built or modified. Here's an example of some of the triples associated with the Cixiang Monastery:
<http://lod.vanderbilt.edu/historyart/site/Cixiangsi>
gn:featureCode gn:S.ANS;
rdfs:label "慈相寺"@zh-hans;
rdfs:label "Cixiangsi"@zh-latn-pinyin;
rdfs:label "Cixiang Monastery"@en;
dcterms:temporal _:3f1c0a54-58d7-4664-bcf5-abe0ca73bbda;
a geo:SpatialThing.
_:3f1c0a54-58d7-4664-bcf5-abe0ca73bbda
time:intervalStartedBy <http://n2t.net/ark:/99152/p0fp7wvjvn8>;
time:intervalFinishedBy <http://n2t.net/ark:/99152/p0fp7wvtqp9>;
rdfs:label "北宋至清"@zh-hans;
rdfs:label "Northern Song to Qing"@en;
a dcterms:PeriodOfTime, time:ProperInterval.
Two resources are described here: the Cixiang Monastery site itself, and the time interval of its construction. The time interval is defined by links to URIs in the PeriodO gazetteer for the starting and ending dynasties. Those URIs dereference, and their associated RDF metadata describe the dynasty periods using the W3C Time Ontology. So in theory, a client that was programmed to "understand" the Time Ontology could "figure out" whether a particular dynasty selected by the user was within the range spanned by a temple site. However, I don't have such a client and I want to do the job with a generic SPARQL query.
The Geological timescale example provided in the Time Ontology specification suggests a useful strategy. In that example, each of the sequential Periods in the timescale are related to the period before and the period after by the predicate time:intervalMetBy, which has this definition: "If a proper interval T1 is intervalMetBy another proper interval T2, then the beginning of T1 is the end of T2."
Unfortunately, the Chinese dynasties are more complicated than the geological time scale because there were dynasties that occurred at the same time in different geographic areas. I looked at all of the different dynasty ranges specified in Tracy's data (using a SPARQL SELECT DISTINCT query - are you surprised?), then tried to diagram out the dynasties in a way that would be amenable to describing their relationships using time:intervalMetBy. To simplify things, if the data said that the site interval started with the generic dynasty "Song", I used the IRI for Northern Song as the starting IRI, and if the interval ended with "Song", I used the IRI for Southern Song as the ending IRI.

For the later dynasties that are completely sequential, it's straightforward - I can just say something like:
<http://n2t.net/ark:/99152/p0fp7wvtqp9> #Qing
time:intervalMetBy <http://n2t.net/ark:/99152/p0fp7wv2s8c>. #Ming
time:intervalMetBy <http://n2t.net/ark:/99152/p0fp7wv2s8c>. #Ming
However, in the middle of the diagram where there were different dynasties in the northern and southern parts of China, it gets more complicated. Some places that were under the control of the Northern Song dynasty eventually came under the Jin Dynasty, while other areas in the south remained under the (Southern) Song Dynasty. (My apologies to Chinese historians if I don't have this exactly right - I read up on this on the Internet.) Also, the starting time of the Liao Dynasty predates the end of the Five Dynasties period. So this diagram may be somewhat of an oversimplification. Nevertheless, I went with it.
Here's how I modeled the relationships:
<http://n2t.net/ark:/99152/p0fp7wvtqp9> #Qing
time:intervalMetBy <http://n2t.net/ark:/99152/p0fp7wv2s8c>. #Ming
<http://n2t.net/ark:/99152/p0fp7wv2s8c> #Ming
time:intervalMetBy <http://n2t.net/ark:/99152/p0fp7wvvrz5>. #Yuan
<http://n2t.net/ark:/99152/p0fp7wvvrz5> #Yuan
time:intervalMetBy <http://n2t.net/ark:/99152/p0fp7wvmghn>. #Jin
<http://n2t.net/ark:/99152/p0fp7wvvrz5> #Yuan
time:intervalMetBy <http://n2t.net/ark:/99152/p0fp7wv9x7n>. #Southern Song
<http://n2t.net/ark:/99152/p0fp7wv9x7n> #Southern Song
time:intervalMetBy <http://n2t.net/ark:/99152/p0fp7wvjvn8>. #Northern Song
<http://n2t.net/ark:/99152/p0fp7wvmghn> #Jin
time:intervalMetBy <http://n2t.net/ark:/99152/p0fp7wvjvn8>. #Northern Song
<http://n2t.net/ark:/99152/p0fp7wvmghn> #Jin
time:intervalMetBy <http://n2t.net/ark:/99152/p0fp7wvw8zq>. #Liao
<http://n2t.net/ark:/99152/p0fp7wvjvn8> #Northern Song
time:intervalMetBy <http://n2t.net/ark:/99152/p0fp7wv5h26>. #Five Dynasties
<http://n2t.net/ark:/99152/p0fp7wv5h26> #Five Dynasties
time:intervalMetBy <http://n2t.net/ark:/99152/p0fp7wvrjpj>. #Tang
time:intervalMetBy <http://n2t.net/ark:/99152/p0fp7wv2s8c>. #Ming
<http://n2t.net/ark:/99152/p0fp7wv2s8c> #Ming
time:intervalMetBy <http://n2t.net/ark:/99152/p0fp7wvvrz5>. #Yuan
<http://n2t.net/ark:/99152/p0fp7wvvrz5> #Yuan
time:intervalMetBy <http://n2t.net/ark:/99152/p0fp7wvmghn>. #Jin
<http://n2t.net/ark:/99152/p0fp7wvvrz5> #Yuan
time:intervalMetBy <http://n2t.net/ark:/99152/p0fp7wv9x7n>. #Southern Song
<http://n2t.net/ark:/99152/p0fp7wv9x7n> #Southern Song
time:intervalMetBy <http://n2t.net/ark:/99152/p0fp7wvjvn8>. #Northern Song
<http://n2t.net/ark:/99152/p0fp7wvmghn> #Jin
time:intervalMetBy <http://n2t.net/ark:/99152/p0fp7wvjvn8>. #Northern Song
<http://n2t.net/ark:/99152/p0fp7wvmghn> #Jin
time:intervalMetBy <http://n2t.net/ark:/99152/p0fp7wvw8zq>. #Liao
<http://n2t.net/ark:/99152/p0fp7wvjvn8> #Northern Song
time:intervalMetBy <http://n2t.net/ark:/99152/p0fp7wv5h26>. #Five Dynasties
<http://n2t.net/ark:/99152/p0fp7wv5h26> #Five Dynasties
time:intervalMetBy <http://n2t.net/ark:/99152/p0fp7wvrjpj>. #Tang
This graph is available in Turtle serialization as a file from the working group GitHub site.
This set of relationships now provides a way to describe "before" and "after" relationships using SPARQL property paths. If I want to query for all dynasties including and after the Jin Dynasty, I can use this triple pattern:
?dynasty time:intervalMetBy* <http://n2t.net/ark:/99152/p0fp7wvmghn>.
where the star after time:intervalMetBy is the "zero to many links" SPARQL property path operator. I can use two of these types of statements to indicate that a dynasty must fall within or between two dynasties. If a site has a time interval ?interval ranging from ?startDynasty to ?endDynasty, I can determine whether that interval includes a particular dynasty (e.g. the Yuan dynasty) using this query fragment.
?interval time:intervalStartedBy ?startDynasty.
?interval time:intervalFinishedBy ?endDynasty.
# target dynasty must be earlier than ?endDynasty
?endDynasty time:intervalMetBy* <http://n2t.net/ark:/99152/p0fp7wvmghn>. #test with Yuan
#target dynasty must be later than ?startDynasty
<http://n2t.net/ark:/99152/p0fp7wvmghn> time:intervalMetBy* ?startDynasty. #test with Yuan
In the program, the URI for the particular dynasty of interest is selected using the dynasty dropdown list. Then that URI is inserted in the query from the Javascript variable (set by the dropdown) into the place where <http://n2t.net/ark:/99152/p0fp7wvmghn> is shown in the example. A particular ?interval value is bound if both the "earlier" and "later" triple patterns are satisfied for the selected dynasty.
You can see an example on line 286 of the tang-song.js file. That's the section of the code that constructs the query to be sent when the Search button is clicked. The same pattern is used at line 115 in the function that screens the site options.
The main point
This example illustrates the generic nature by which data can be acquired from the server via a SPARQL query. If I want my client application to screen sites by dynasty, I don't have to ask the server administrator to create server-side code that would enable me to get that information via an API. I decide about the kind of information that I'm going to get by the way that I design the SPARQL query that I send to the endpoint. Essentially, every user can design a personalized API that does exactly what they want, rather than relying on the server administrator to create an API that will satisfy all of the kinds of things that the users might want.
Because the nature of the data that is retrieved from the endpoint is not fixed, the actual code that constructs the query can be modified on the fly by the user based on what happens during the interaction with the endpoint. I've thought about programming a generic data exploration page where the properties screened by the dropdowns were not fixed. The user could ask the endpoint what properties were used with a certain class of resources, then select which properties to use for each of several dropdowns. The web application would then ask the endpoint to return the possible values for each property chosen by the user and then set the values in those dropdowns to those values that were retrieved. The application would look similar to the Temples search page, but instead of the dropdowns being fixed as "Dynasty", "Province", etc., they could be any kind of information available in the triplestore about a class of resources.
Sometime when I have more time, I'm going to try programming that!
[1] It's hacked from an earlier page that we created as part of Sean King's 2015 Dean's Fellow project, for which Suellen Stringer-Hye and I served as co-mentors. Jodie Gambill made major contributions towards styling the HTML and making the page work better.
No comments:
Post a Comment